RCarpenter
Member
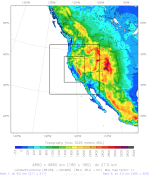
I am using WRF v4 to run yearly reanalyses on a nested grid, and am having difficulties that I hope you can help me diagnose. I’m attaching the namelist.wps and namelist.input files as well as a plot of the domain. The grid is 27/9/3 km, with the outer grid covering W CONUS and the adjacent Pacific and the inner grid covering most of California. The problem is that the runs are dying without giving any error messages. The rsl files stop growing, yet the job continues to run without producing further output. Unfortunately, this makes it difficult to diagnose the underlying problem. I have tried many different options, but perhaps not the right set. Let me start with some observations:
Some general questions:
And now some questions related to various options:
Apologies for the long letter, and thank you for your help.
- I am using CFSv2 reanalysis data. The runs are initialized on July 29 of various years. The runs tend to crash at various times, but generally run for at least several days before the first crash.
- The runs die without producing any error output. (Actually they continue to run without producing any further output.) I have searched the logs for statements about CFL errors but have not found anything. When running with debugging on, in one instance one processor’s last call was to SFCLAY.
- The problems do not seem to be related to the computing system. I have tried varying the number of processors, quilting, etc. The runs often fail in the middle of an hour, indicating it is not an I/O issue. System logs do not indicate any problems, and a host of other unrelated WRF runs do not have any issues.
- In most cases near the time of the crash there is a strong dynamical feature that I suspect is causing numerical instability. Near the outer grid boundary, there have been small-scale convection resulting in vertical velocities of ±6 m/s; a hurricane; and upper-level jet gradients. On the 3-km grid, strong vertical motion (±6 m/s) is noted in steep terrain in the lee of the Sierra Nevada and other S Calif mountain ranges.
- After a crash, the runs are restarted. Sometimes they are restarted without changing any dynamics settings, and sometimes (but not always), the runs proceed past the point where they initially failed. Other times, I have changed the settings (usually to reduce the timestep), and the runs will proceed for a while. But they always fail at some point.
- I am using adaptive timestepping. I have adjusting some of the settings, including setting target_cfl and target_hcfl to small values (0.3 and 0.2). I’ve also tried adjusting max_step_increase_pct (25, 51, 51) and setting adaptation_domain to one of the nests. None of these solved the underlying problem, although they did reduce the timestep to 81/27/9 at times. A test with a fixed timestep of 120 also failed.
- These failures have been noted with the YSU scheme (bl_pbl_physics=1, sf_sfclay_physics=1, sf_surface_physics=2). When the MYJ scheme is used (2, 2, 2), the runs do not crash – they continue for a full 365 days.
- Similarly, real-time runs using the YSU scheme do not crash. These runs have the same grid and same physics/dynamics options, but are initialized with 0.25° GFS.
Some general questions:
- Why would a run with MYJ succeed while YSU runs fail?
- Why would real-time YSU runs succeed while reanalysis runs fail?
- Are these failures consistent with numerical instability, even though no CFL violations are reported?
And now some questions related to various options:
- In the User’s Guide there is a recommendation for boundary relaxation for regional climate runs (wider relaxation zone, exponential decay factor). Are these settings also recommended for long runs involving nested grids? It seems that what may be optimal for the outermost grid may not be optimal for the nests.
- If I understand correctly, setting diff_6th_slopeopt=1 turns OFF 6th-order diffusion in steep terrain. What would you recommend for this option (because of the very steep terrain that exists on the 3-km grid)?
- I have observed that a run that has been restarted following a crash will sometimes continue past the point of the crash, even if there have been no changes to the namelist, other than those specifically related to restarting. Could it be that restarts with adaptive timestepping aren’t bit-reproduceable?
- Can you explain the interplay between target_[h]cfl and adaptation_domain? What happens if the target CFL is exceeded on grid 3 but the adaptation_domain is grid 1?
- I have observed cases where the 3-km grid timestep is half that of the 9-km grid, even though parent_time_step_ratio = 1, 3, 3. In other words, the ratio is 2:1 instead of the expected 3:1. For instance, the timesteps might be 81/27/13.5. Is this to be expected?
Apologies for the long letter, and thank you for your help.